雷達和無線電系統從模擬信號處理逐漸發展到數字信號處理,促進了波束形成技術的發展,并由此帶來了波束形成技術的革新。高精度的波束數字化處理能力,可以徹底改變未來的商用和軍用雷達系統設計。
自適應波束形成算法采用浮點算法進行信號處理,通過同時發射多個點波束各自進行實時目標跟蹤,可以提高雷達性能。
改進的格拉姆-施密特(MGS)矩陣分解(QRD)和權值回代算法(WBS)是雷達DSP芯片的重要算法,可以使雷達在抑制旁瓣、噪聲和干擾的同時自適應波束形成。這些算法需要非常高的每秒浮點運算次數(FLOPS)。
Xilinx公司的FPGA芯片的浮點運算能力,比商用GPU、DSP和多核CPU芯片要高幾個數量級。
HLS是Xilinx公司的Vivado®設計套件的一個標準工具,支持本地C語言編碼設計。自適應波束形成的核心是一種浮點矩陣求逆算法,這種算法目前可通過本地C/C++語言或Xilinx公司的Vivado HLS SystemC語言編碼設計。
本文關注的是一個復浮點函數,可變大小的改進的格拉姆-施密特(MGS)矩陣分解(QRD)和權值回代算法(WBS),復浮點函數大小為128x64。
一、引言
目前,大多數雷達都采用了某種類型的自適應數字波束形成技術。接收波束形成概念如圖1所示。
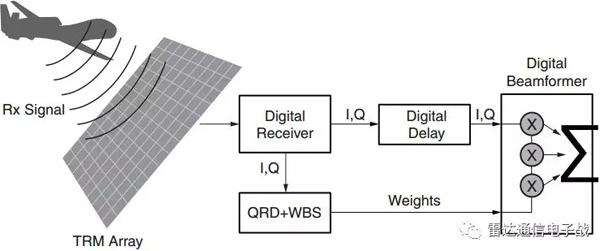
圖1、自適應數字波束形成
雷達設計占用的帶寬越來越高,要求接收系統更加可靠地抑制以下幾方面:一是噪聲源干擾,二是目標以外的天線旁瓣,三是敵方干擾信號的干擾,四是新型雷達技術的寬帶寬特性引起的“雜波”。
在定向控制每個天線陣列期間必須完成上述處理:分別處理、同時處理或者實時處理。在給定的時間范圍內,通過單元級處理可以成功完成這些任務,即分別或同時對每個天線單元的接收信號進行數字化處理。
自適應數字波束形成是單元級處理的重要部分。本文重點介紹了自適應波束形成技術,以及如何采用Xilinx公司的FPGA芯片構建一種比傳統雷達系統成本更低、結構更復雜、功耗更大、上市時間更短的波束捷變雷達系統。
利用本文敘述的技術和Xilinx公司的組件,通過計算復浮點函數的自適應權值,可以實現波束捷變雷達。這些權值基于前一個脈沖重復間隔(PRI)緩存的復雜接收信號樣本子集。計算這些權值的挑戰在于,需要進行復矩陣求逆,在接收下一個脈沖重復間隔數據之前解公式1。
需要一個確定的、低延遲的矩陣大小,該矩陣大小是雷達系統需求的函數。傳統上,這種算法是由許多并行CPU芯片執行的,確保在下一個脈沖重復間隔之前完成浮點運算。
考慮到許多雷達/電子戰系統的尺寸、重量和功率(SWaP)限制,CPU/GPU芯片不是完成這些運算的最佳選擇。Xilinx公司的FPGA芯片采用的硬件較少,可以更有效地執行高并行的浮點算法。
Xilinx公司的FPGA芯片具有兼容性,雷達設計者可以通過兼容的I/O標準(例如JESD204B、SRIO、PCIe®等)處理大量的數據,然后實時計算FPGA芯片的自適應權值。需要求解的線性方程在如圖1所示的QRD+WBS算法功能框圖中,公式1的數學表達式為:

x=求解的復向量,變成自適應權值,大小(n,1)
b=期望響應或導向矢量,大小(m,1)
為了求解x,不能直接用b除以A。改進的格拉姆-施密特(MGS)矩陣分解(QRD)算法需要計算矩陣求逆。改進的格拉姆-施密特(MGS)矩陣分解(QRD)算法必須采用浮點運算,以保持自適應權值的精度。
二、Vivado HLS概述
Vivado HLS工具采用C/C++語言作為硬件設計的源程序,將驗證時間減少幾個數量級,顯著加快了運算速度。針對硬件的目標算法,通常需要輸入大量的測試向量集,以確保正確的系統響應。
采用RTL和基于事件的RTL模擬器時,可能需要數小時甚至數天才能完成模擬。然而,采用C/C++語言時,模擬速度可以加快10000倍,能夠在幾秒或者幾分鐘內完成模擬。每天通過更多的交互設計,設計者能夠以更快的驗證時間加速研發。如圖2所示。
除了驗證時間更快之外,Vivado HLS還支持高階設計檢索,用戶可以在不修改源代碼的情況下,快速檢索多個硬件體系結構的不同區域并進行性能權衡。這可以通過合成指令實現,例如loop unrolling和pipeline insertion。
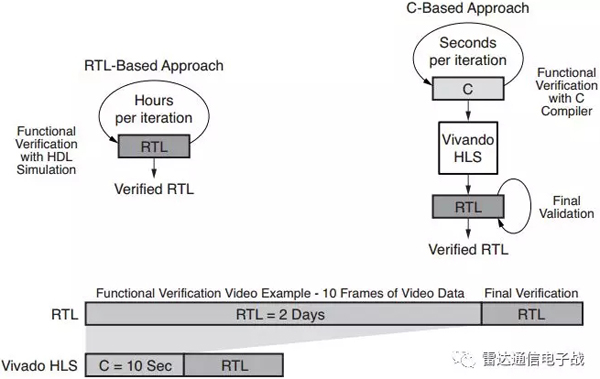
圖2、基于RTL和基于C語言的迭代研發時間
采用標準的數學函數,Vivado HLS加載了C/C++語言編程的線性代數函數庫,通過HLS可以合成這些函數庫,并優化結果。研發這些功能是為了讓用戶充分利用Vivado HLS的設計檢索(包括loop unrolling和pipeline register insertion),使用戶能夠非常靈活地生成滿足設計需求的硬件體系結構。
用戶可以修改這些函數的源代碼,這些功能作為設計工作的起點,在最終啟用時有更大的靈活性。函數庫包括以下功能和支持的數據類型(詳見表1):
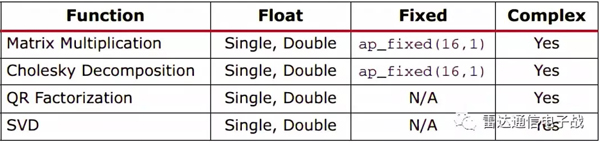
表1、Vivado HLS中的函數/數據類型
三、QRD和WBS算法
QRD將復矩陣A轉換為:
Q:是一個大小(m,n)的正交矩陣
R:是大小(m,n)的上三角矩陣,或右三角矩陣。它稱為三角形,下方的三角形值都為0。這樣使求解x的運算速度很快。
為簡單起見,MGS算法采用Octave或MATLAB®代碼,如圖3所示。

圖3、MGS QRD算法
通過回代,解出x。
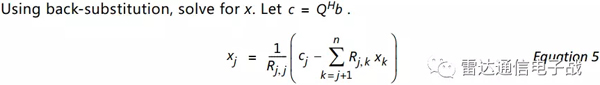
四、基于CPU和FPGA芯片的波束形成體系結構
當功能不適合單個設備時,后果可能非常嚴重,導致內存、接口、有效面積、集成時間、成本和功率的增加。
(一)多CPU芯片體系結構
當采用多個CPU芯片的老方法實現自適應波束形成時,可能會出現上述情況。通過QRD+WBS算法對16個通道進行波束形成大約需要3.5ms。基于CPU芯片的設計不僅不適合單個設備,它需要更深入的系統設計、認證和集成,且功耗很大。
論證的結果是,每個CPU芯片核需要250ms執行128×64浮點數的復雜QRD+WBS算法(這是保守估計,因為沒有考慮內存存取和調度時間)。用250ms除以3.5ms,需要72個CPU芯片核執行QRD算法。CPU芯片設計時對系統設計者進行了限制,只預留了非常有限的一組內存和外部接口。
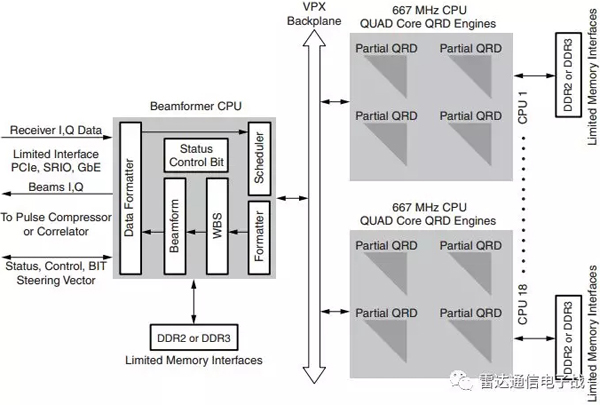
圖4、采用18個CPU芯片(72核)的自適應波束形成
6個CPU芯片板(每個芯片板安裝3個CPU 芯片,每個CPU芯片有4核,合計72核),加上一個波束形成主板,總共7個板,每個板功耗約200瓦,總功耗約1400瓦。當然,可以采用更高的CPU芯片時鐘頻率(功耗更大),但是CPU芯片的功耗仍沒有FPGA芯片的功耗好。如圖4所示,這是一個CPU芯片的體系結構,需要18個CPU芯片。
(二)Xilinx公司的單個FPGA芯片體系結構
Xilinx公司的FPGA芯片很容易安裝在Virtex7 FPGA芯片組中。單個FPGA芯片安裝在電路板上,該電路板還安裝了外部內存和其他輔助功能裝置,單個電路板的總功耗約75瓦。
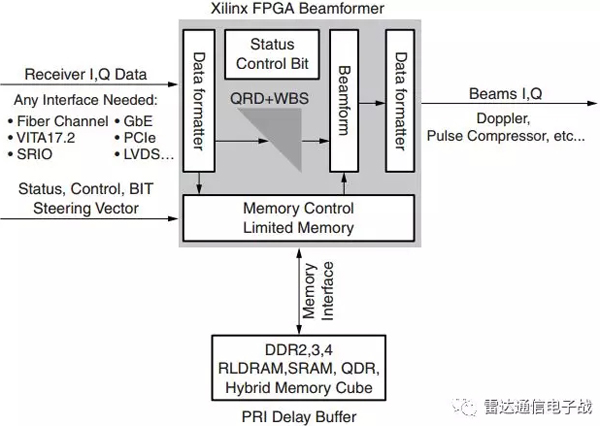
圖5、采用單個Virtex-7 FPGA芯片的自適應波束形成
在解決相同問題時,與VPX底板安裝18個CPU芯片相比(如在多CPU芯片體系結構中敘述的那樣),顯然CPU芯片的功耗與FPGA芯片的功耗不匹配。
五、采用Vivado執行MGS QRD+WBS算法
Vivado HLS使任何算法都可以通過C/C++語言或SystemC語言編程,它為Xilinx公司的所有FPGA芯片的Vivado工具流,創建了一個靈活、可移植、可升級的核。設計流程如圖6所示。

圖6、自適應波束形成的設計流程
由于MATLAB可以編譯C/ C++語言,稱為MEX (MATLAB可執行程序),用戶可以調用C/ C++代碼,而不用調用等效的MATLAB函數。這意味著只有一個主模型和代碼,大大減少了測試和集成的設計。設計時間通常為幾個月到幾天,與編寫VHDL/Verilog代碼相比,命令集減少了。
設計時間的減少源自以下兩個方面:
1. 通過可執行文件運行的C/ C++語言模擬,只需要幾秒鐘就可以驗證設計的反應時間和數值。門級RTL模擬是迭代的,速度慢10000倍。因此,一旦發現錯誤需要立即糾正,然后在RTL中重新模擬。
這種循環甚至會導致最簡單的設計也會影響成本和進度。Vivado HLS的設計第一次是正確的。由于加快了系統集成時間,在設計階段更容易盡早發現設計錯誤。
2. 采用C/ C++語言或SystemC語言模型設計,這意味著設計總是可移植、靈活和可升級的。設計者不會拘泥于特定的FPGA芯片或芯片組。
用戶可以立即更換FPGA芯片空間,為這個設計挑選最適合的芯片(不需要猜測),因為HLS工具的輸出公布了PFGA芯片的時鐘、延遲和資源占用。
(一)最初的通道結果
VivadoHLS工具的輸出結果可以在幾秒鐘內顯示出來,如圖7所示:

圖7、算法的第一次結果
需要注意時鐘周期和最差延遲。對于特定的運算,MGS QRD+WBS算法大約需要10ms得出結果。它采用DSP48芯片和RAM模塊。對某些雷達系統而言,這種延遲是可以接受的。
(二)采用指令傳遞的結果
采用的指令證明了Vivado HLS的功能。只需簡單將C語言代碼中的一些FOR循環展開16倍,對RAM模塊進行分區,設計者通過PIPELINE指令可以得出令人震驚的結果,如圖8所示。采用C/C++語言修改矩陣大小很簡單,但如果采用HDL作為設計語言,情況就并非如此。

圖8、算法采用指令后的結果
Xilinx公司的FPGA芯片的純DSP密度是該解決方案的重要指標。MGS QRD + WBS算法只采用了392個DSP48芯片。這為自適應波束形成和雷達DSP信號處理預留了很大空間,例如脈沖壓縮、多普勒濾波和恒虛警率(CFAR)。
如圖9所示,這是一部分C語言代碼示例,重點是編碼風格和指令。如果這段代碼用C++語言編程,設計者可以調用內置的復雜數學函數庫。當不需要進行浮點運算時,Vivado HLS也支持定點運算。

圖9、顯示編碼風格和指令的C語言代碼示例
由于采用C/C++語言設計,因此更改矩陣的大小非常簡單。采用VHDL/Verilog人工編碼是不現實的。Vivado HLS還支持多種接口,例如FIFO、RAM模塊、AXI和各種信號交換接口。芯片核也有全核控制的時鐘,同步復位,開始,完成和空閑信號。
六、結果
Virtex-7 1140T FPGA芯片的Vivado HLS軟件的結果匯總在表2中。該設計是MGS QRD+WBS算法芯片核,支持最多128個變量行和最多64個變量列。
采用Virtex-7 FPGA芯片的系統成本比采用ARM-A9 CPU芯片的系統成本低大約12.5倍。如表2所示,采用Xilinx公司的Vivado HLS工具,可以在3.3 ms內處理128×64浮點函數。
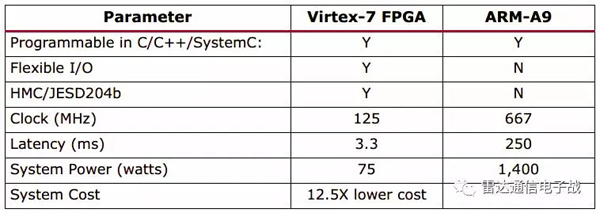
表2、MGS QRD+WBS算法比較
在667 MHz的ARM Cortex-A9芯片上執行同樣的代碼,會產生250ms的延遲。這種比較凸顯了一個事實,即Xilinx公司有一套滿足一系列設計需求的完備的可編程邏輯組合,從低延遲解決方案到采用ARM A9處理器的高度集成的Zynq-7000 APSoC解決方案。
用戶采用Vivado HLS,無需通過長時間的RTL模擬,就可以快速更換設備、區域、延遲和時鐘頻率的空間。采用C/ C++語言,可以將代碼無縫鏈接和無限制地從Xilinx公司的可編程邏輯組合移植到Zynq-7000 AP SoC。
該設計采用了三個指令:unrolling、pipelining和RAM模塊分區。該設計大約4小時完成,需要對模擬數據進行多次算法模擬。該設計如果采用VHDL/Verilog人工編碼,并進行RTL驗證,可能需要幾周甚至幾個月的時間,取決于設計者的技能。
七、結論
本文論述了Xilinx公司的FPGA芯片可以采用Vivado HLS在C/C++語言中編程,解決了所有雷達或無線系統面臨的一項最復雜的挑戰:采用MGS QRD+WBS算法進行復矩陣求逆。并行浮點運算和本地C語言開發的好處顯而易見。
本地C語言設計的HLS優勢,使Xilinx公司的FPGA芯片的性能和低功耗,優于所有FPGA芯片競爭對手和CPU/DSP/GPU芯片。Xilinx公司的7系列FPGA芯片(及以上產品),采用了先進的Vivado和HLS設計流程,各個方面都優于GPU、DSP和CPU芯片。
本文來源Xilinx手冊,屬于用戶翻譯內容,供大家參考。
 粵公網安備 44030902003195號
粵公網安備 44030902003195號